
















在复杂数据模型中,常常会遇到文档中包含数组对象的场景,例如订单中包含多个商品、日志中包含多个事件详情等。在这种情况下,如何对数组内部的数据进行准确统计分析,是聚合分析中的常见需求。
Easysearch 支持嵌套(nested)聚合和反向嵌套(reverse_nested)聚合,帮助开发者针对嵌套对象字段进行精细统计和关联分析。本文从基础讲起,结合实例与可视化思路,带你快速掌握这两种高级聚合方式。
1. 简要回顾 Easysearch #
Easysearch 是一款分布式搜索型数据库,兼具全文检索、结构化检索和聚合分析能力。聚合功能允许对搜索结果进行统计分析,比如求平均值、最大值、按分组统计等,是构建可视化统计面板和业务分析平台的重要基础。聚合的基本语法结构如下:
GET /your_index/_search
{
"size": 0,
"aggs": {
"agg_name": {
"AGG_TYPE": {}
}
}
}
其中 "size": 0 表示我们只关心聚合统计结果,不返回具体文档内容。
2. 为什么要用嵌套聚合 #
在 JSON 文档中,数组类型的对象字段默认是以普通对象方式存储的(object type),这种存储模式下的多值对象在搜索和聚合时可能会混淆不同元素之间的关系。例如,一个用户文档包含:
{
"id": "1",
"tags": [
{ "type": "feature", "flag": 1 },
{ "type": "bug", "flag": 0 }
]
}
如果你想统计所有 "flag":1 的 type,普通聚合可能会把 tag.type 与 flag 值错误地组合起来,无法确保它们来自同一个对象元素。这时就需要将字段 mapping 定义为 nested 类型,这样每个子对象会作为单独的索引单元进行统计,避免不正确的组合匹配情况。
3. 嵌套聚合(nested):聚合数组对象内部字段 #
3.1 什么是 nested 聚合
#
**嵌套聚合(nested aggregation)**允许我们对嵌套对象字段内的属性进行独立的聚合统计,而不会混淆同一个文档中的不同对象元素值。嵌套字段在映射中定义为 nested 类型。
3.2 示例:统计嵌套对象字段 #
假设我们有一个订单索引,每个订单包含多个商品:
PUT orders/_doc/1
{
"order_id": "1001",
"items": [
{ "product": "A", "price": 100 },
{ "product": "B", "price": 150 }
]
}
其中 items 在映射中定义为 nested 类型。
为了统计所有嵌套商品的平均价格,可以写如下聚合:
GET orders/_search
{
"size": 0,
"aggs": {
"nested_items": {
"nested": {
"path": "items"
},
"aggs": {
"avg_price": {
"avg": {
"field": "items.price"
}
}
}
}
}
}
这个聚合将:
- 进入嵌套对象
items; - 对
items.price字段做平均值统计。
返回结果中 avg_price.value 就是所有嵌套商品的平均价格。
3.3 嵌套聚合常见用处 #
嵌套聚合适合场景包括:
- 产品评价中统计每个用户的评论分布;
- 日志中多条事件统计某个字段的统计信息;
- 订单中按嵌套项计算指标(如总销售额、最小价格等)。
4. 反向嵌套聚合(reverse_nested):从子对象跳回父级 #
4.1 什么是 reverse_nested 聚合
#
在执行嵌套聚合后,有时我们希望跳回嵌套对象所属的父文档级进行分析,这时就需要 reverse_nested 聚合。它允许在嵌套聚合内部“往回走”,把聚合上下文从子对象返回到父文档或上一级嵌套对象。
反向嵌套聚合必须定义在 nested 聚合内,因为它是基于嵌套结构“回溯”实现的。
4.2 示例:统计存在某嵌套项的父文档数量 #
假设订单文档除了嵌套 items 之外,还有一个主字段 customer_id。我们希望:
统计每个顾客有多少订单,其中至少包含价格大于 100 的商品。
示例聚合如下:
GET orders/_search
{
"size": 0,
"aggs": {
"nested_items": {
"nested": {
"path": "items"
},
"aggs": {
"price_gt_100": {
"filter": {
"range": {
"items.price": { "gt": 100 }
}
},
"aggs": {
"back_to_order": {
"reverse_nested": {},
"aggs": {
"customers": {
"terms": { "field": "customer_id" }
}
}
}
}
}
}
}
}
}
这个查询逻辑:
- 在嵌套对象
items中筛选出价格大于 100 的商品; - 使用
reverse_nested回到订单文档级; - 在订单级统计订单所属的顾客分布。
这样就能统计:哪些顾客的订单中包含价格大于 100 的商品,以及对应订单数量。
5. 可视化实践示例 #
聚合结果通常是结构化的 JSON,但可视化才能让人直观理解数据分布与趋势。这里以图表方式展示两种典型聚合:
5.1 嵌套聚合 — 嵌套对象字段的柱状图 #
假如我们统计了嵌套对象中商品的平均价格,返回结果可能类似:
{
"aggregations": {
"nested_items": {
"avg_price": {
"value": 125.4
}
}
}
}
前端可以提取 avg_price.value 并渲染一个 KPI 指标卡:
const avgPrice = response.aggregations.nested_items.avg_price.value;
document.getElementById("avgPrice").textContent = avgPrice.toFixed(2);
5.2 反向嵌套聚合 — 分类统计饼图 (客户订单分布) #
假设我们通过 nested + reverse_nested 聚合,得到了「包含指定商品条件的订单,在不同客户之间的分布情况」。下面我们将结果使用 饼图(Pie Chart) 来展示占比关系。:
{
"aggregations": {
"nested_items": {
"price_gt_100": {
"back_to_order": {
"customers": {
"buckets": [
{ "key": "cust_A", "doc_count": 23 },
{ "key": "cust_B", "doc_count": 15 },
{ "key": "cust_C", "doc_count": 8 }
]
}
}
}
}
}
}
含义很直观:
cust_A:23 个订单cust_B:15 个订单cust_C:8 个订单
2. 前端数据转换(适配 ECharts) #
ECharts 饼图要求的数据格式为:
[
{ name: 'xxx', value: number },
...
]
可以这样处理聚合结果:
const buckets =
response.aggregations.nested_items.price_gt_100.back_to_order.customers
.buckets;
const pieData = buckets.map((item) => ({
name: item.key,
value: item.doc_count,
}));
此时 pieData 即可直接用于饼图。
3. ECharts 饼图完整配置示例 #
const option = {
title: {
text: "客户订单分布",
subtext: "包含高价商品的订单",
left: "center",
},
tooltip: {
trigger: "item",
formatter: "{b}: {c} 单 ({d}%)",
},
legend: {
orient: "vertical",
left: "left",
},
series: [
{
name: "订单数量",
type: "pie",
radius: "60%",
center: ["50%", "55%"],
data: pieData,
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
},
},
},
],
};
chart.setOption(option);
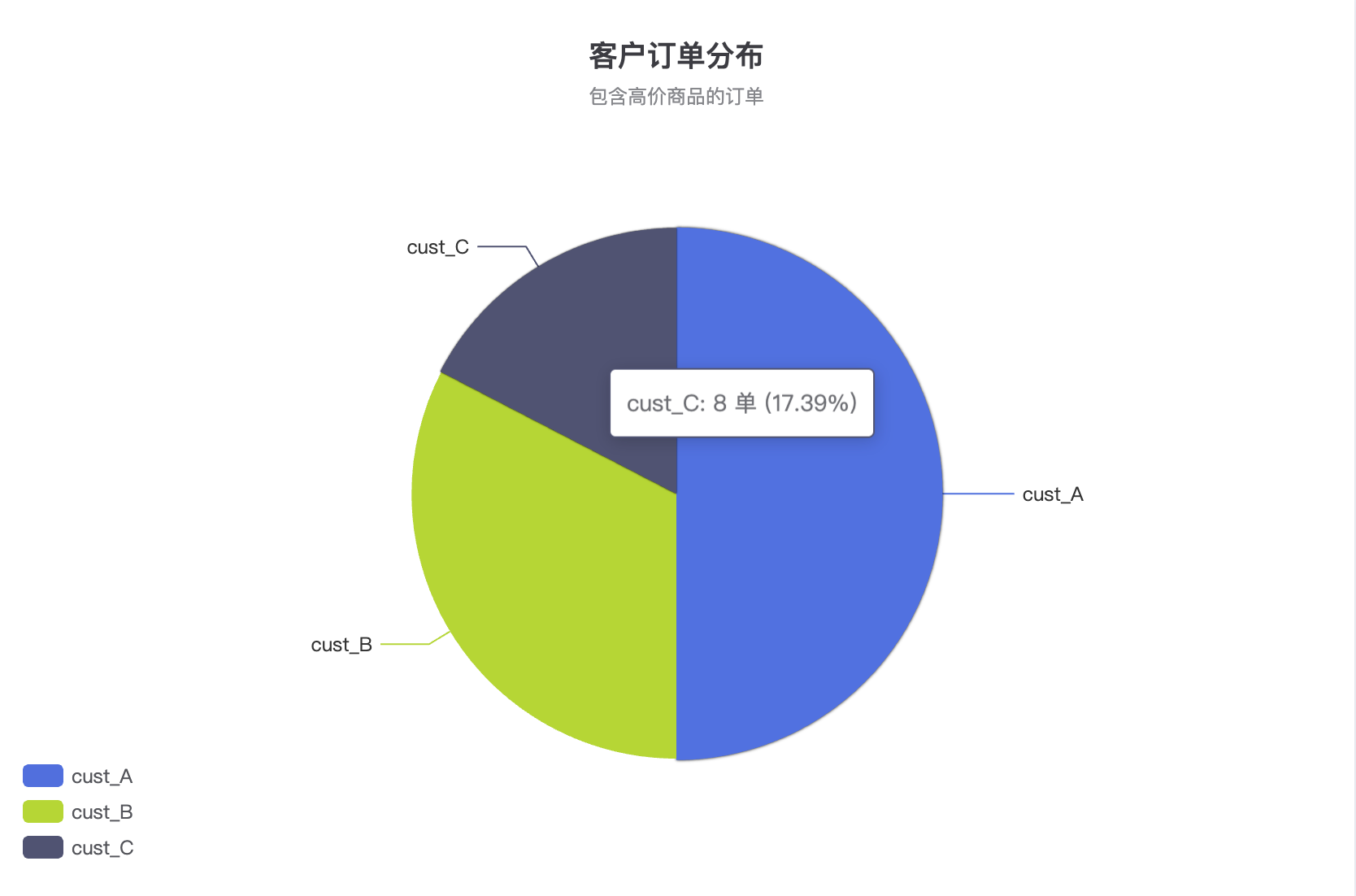
4. 图表展示效果说明 #
该饼图能够直观展示:
- 每个客户在订单总量中的占比;
- 哪些客户贡献了更多符合条件的订单;
- 客户分布是否集中或分散。
📊 非常适合用于:
- 客户贡献分析
- 核心客户识别
- 订单结构分析
6. 适用场景与注意事项 #
6.1 什么时候需要 nested #
- 你希望精准统计数组内部对象;
- 数组元素之间字段组合逻辑不可混淆;
- 需要针对子对象做 filter 或 metrics。
在这种情况下,嵌套聚合比普通对象聚合更准确。
6.2 性能与实践建议 #
嵌套聚合和反向嵌套聚合会涉及更多的内部处理,与普通聚合相比性能开销更大。建议:
- 仅在确实需要时使用;
- 尽量减少嵌套层级;
- 可以结合 filter 或 date_histogram 做精确聚合。
7. 总结 #
| 聚合类型 | 作用 | 典型用途 |
|---|---|---|
| nested | 对嵌套对象字段进行聚合 | 数组对象指标统计 |
| reverse_nested | 从嵌套上下文返回父文档聚合 | 在 nested 内进行父级统计 |
Easysearch 的嵌套与反向嵌套聚合提供了对复杂文档结构中字段进行精细分析的能力。通过这种方式,你可以实现更准确的业务指标统计和更深入的数据洞察,是构建搜索分析平台的重要工具之一。

