
















在很多企业项目里,“搜索”早已不是锦上添花,而是支撑 日志检索、告警排查、运营分析、内部统一搜索 的核心底座。
但在工程实践中,团队往往会同时面临两类现实问题:
- DSL 足够灵活,但代码量大、可读性差、维护成本高
- 索引创建/变更、Mapping 升级、数据迁移……一堆“脏活累活”容易出错
- 国产化/信创落地时,希望替换底层引擎,同时又希望尽量不改业务代码
这也是 Easysearch(分布式近实时搜索与分析引擎) 与应用侧生态结合的价值所在:在保持兼容与工程效率的同时,提供更安全稳定、易维护的搜索底座。
而在应用侧,Easy-Es for Easysearch(Easy-Es 2.1.0-easysearch) 给了一个更工程化的答案:
用类似 MyBatis-Plus 的 ORM 方式,完成 Easysearch 的 CRUD、条件构造、高亮、聚合、SQL 查询,让业务研发“像写数据库代码一样写搜索”。
本文不会把重点放在“手把手搭项目”,而是围绕 深度集成 + 生产可用 给出一套可复制的最佳实践,并通过一个典型场景(告警日志检索)跑通关键链路。
1. 为什么是 Easysearch + Easy-Es #
1.1 Easysearch:面向企业的搜索与分析底座 #
企业落地搜索引擎时,通常要兼顾:
- 国产化替代:减少许可证风险与供应链风险
- 稳定与安全:资源保护、容灾、审计、安全能力
- 降本增效:冷热分离、快照、异步查询等能力组合
Easysearch 在兼容 Elasticsearch 的同时,更贴近企业生产环境的工程需求。
1.2 Easy-Es:把搜索“工程化”的 ORM 体验 #
Easy-Es 的价值不是“把 ES 变成数据库”,而是把高频工作工程化:
- 类 MyBatis-Plus 的 Wrapper 条件构造(Lambda 类型安全)
- 自动索引托管:创建 / 更新 / 迁移(支持“平滑模式”)
- 高亮、聚合等能力的封装
- 支持通过 SQL 执行查询(适合作为轻量分析入口)
2. 本文定位:适合谁?不适合谁? #
在进入代码前,先明确本文适用范围。
2.1 适合你,如果你正在做: #
- 从 Elasticsearch 平滑迁移到 Easysearch
- 新建 Easysearch 业务索引,并希望减少 DSL 代码
- 想用更工程化方式管理索引、Mapping 演进、查询封装
- 需要高亮、聚合、SQL 等典型能力
2.2 不适合你,如果你期待: #
- 完全不理解 term/match/agg 也能“无脑 ORM 化”
- 用 SQL 替代所有 DSL 查询
- 用 Easy-Es 完成复杂 OLAP / 多表 JOIN / 任意分析
最健康的状态是:80% 查询 ORM 化,20% 保留原生能力与工程边界。
3. 整体架构:深度集成的请求链路 #

图1:Spring Boot + Easy-Es + Easysearch 的请求链路
4. 先读:深度集成的 6 条最佳实践原则 #
这 6 条原则决定了你是否能把 Easy-Es 用得“像工程”,而不是“像 Demo”。
原则 1:索引是契约 #
索引字段类型、Analyzer、keyword/text 的选择,本质上是接口契约。
一旦上线,尽量只增不改。字段类型变更属于高风险操作,可能导致:
- 写入失败
- 查询结果异常
- 必须全量重建数据
原则 2:ORM 是降噪,不是屏蔽搜索引擎 #
Easy-Es 能降低 DSL 噪音,但团队仍应理解:
eq对应 term 查询match对应全文检索groupBy对应 terms 聚合- refresh/分页/聚合对性能的影响
否则很容易写出“看似 ORM,实则慢查询”的代码。
原则 3:SQL 入口只能作为辅助通道 #
SQL 能力非常适合:
- 轻量分析
- 运营临时查询
- 验证数据
但它不适合做:
- 高并发业务接口
- 任意字段查询入口
- 未授权的“万能检索通道”
SQL 入口必须做:鉴权 + 审计 + 参数白名单 + 限流。
原则 4:刷新策略不要默认 immediate #
很多团队为了“实时”,直接把 refresh-policy 设为 immediate。
这会显著增加写入成本,吞吐下降明显。
日志/告警通常可接受秒级可见,更温和的策略更合理。
原则 5:深分页必须提前设计替代方案 #
from + size 深分页的代价会随着页数指数级变高。
需要深分页时,应优先考虑:
- search_after(推荐)
- scroll(按业务场景)
原则 6:索引托管模式要分环境选择 #
- 开发/迭代期:
smoothly - 生产期:仍需评审、灰度、回滚预案
- 高风险字段变更:优先兼容设计,必要时新建索引重建
5. 快速集成 #
版本基于:easy-es-boot-starter:2.1.0-easysearch
Spring Boot 建议:2.7.x,JDK 8+
因篇幅有限,下文仅介绍关键配置。
5.1 Maven 依赖(最小集) #
<dependencies>
<dependency>
<groupId>org.dromara.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>2.1.0-easysearch</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
5.2 application.yml:最小可用 + 生产建议 #
最小可用配置(必选) #
easy-es:
enable: true
address: localhost:9200
schema: http
global-config:
process-index-mode: smoothly
print-dsl: false
db-config:
index-prefix: dev_
map-underscore-to-camel-case: true
生产建议配置(可选但推荐) #
easy-es:
username: admin
password: your_password_here
keep-alive-millis: 18000
global-config:
db-config:
refresh-policy: wait_until
field-strategy: not_empty
enable-track-total-hits: true
说明:refresh-policy 需要根据业务实时性选择,不建议默认 immediate。
5.3 启动类:扫描 Mapper #
@SpringBootApplication
@EsMapperScan("com.example.demo.mapper")
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
6. 典型场景:告警日志检索 #
这个示例不是为了展示“所有 API”,而是模拟真实生产最常见的搜索场景:
- 按 service + 时间范围 + keyword 检索
- 高亮展示命中内容
- 聚合统计(level/service)
- (可选)SQL 给运营/分析使用
如果你只需要 CRUD 或简单查询,只看 6.1~6.2 即可。
6.1 核心:实体类定义(索引映射 + 字段策略) #
这是 ORM 深度集成的核心:字段类型、Analyzer、keyword/text 选择、高亮映射都在这里。
@Data
@Settings(shardsNum = 3, replicasNum = 1)
@IndexName(value = "alarm_log", keepGlobalPrefix = true)
public class AlarmLog {
@IndexId(type = IdType.CUSTOMIZE)
private String id;
@IndexField(fieldType = FieldType.KEYWORD)
private String service;
@IndexField(fieldType = FieldType.KEYWORD)
private String level; // INFO/WARN/ERROR
@IndexField(fieldType = FieldType.DATE, dateFormat = "epoch_millis")
private Long timestamp;
@HighLight(mappingField = "highlightMessage", preTag = "<em>", postTag = "</em>")
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_MAX_WORD, searchAnalyzer = Analyzer.IK_SMART)
private String message;
@IndexField(fieldType = FieldType.KEYWORD)
private List<String> tags;
private String highlightMessage;
}
字段设计最佳实践(选择与原因) #
service/level/tags用 keyword:过滤与聚合稳定message用 text:全文检索 + Analyzertimestamp用毫秒时间戳:范围查询与排序直观- 高亮通过
@HighLight驱动:业务代码无需额外配置
6.2 Mapper:像 MyBatis 一样写接口 #
public interface AlarmLogMapper extends BaseEsMapper<AlarmLog> {
}
6.3 查询:ORM 风格的 Wrapper(过滤 + 检索 + 排序 + 分页) #
@Service
@RequiredArgsConstructor
public class AlarmLogService {
private final AlarmLogMapper alarmLogMapper;
public List<AlarmLog> search(String service, String keyword, Long start, Long end, int page, int size) {
int safePage = Math.max(page, 1);
int safeSize = Math.min(Math.max(size, 1), 500);
int from = (safePage - 1) * safeSize;
LambdaEsQueryWrapper<AlarmLog> wrapper = new LambdaEsQueryWrapper<>();
if (StringUtils.hasText(service)) {
wrapper.eq(AlarmLog::getService, service);
}
if (start != null) {
wrapper.ge(AlarmLog::getTimestamp, start);
}
if (end != null) {
wrapper.le(AlarmLog::getTimestamp, end);
}
if (StringUtils.hasText(keyword)) {
wrapper.match(AlarmLog::getMessage, keyword);
}
wrapper.orderByDesc(AlarmLog::getTimestamp)
.from(from)
.size(safeSize);
return alarmLogMapper.selectList(wrapper);
}
}
查询侧最佳实践(关键点) #
- 过滤优先用
eq/ge/le(term/range) - 文本检索优先
match,短语用matchPhrase - size 设置上限(例如 500),避免接口被滥用
- 深分页不要长期使用
from + size(见第 8 节)
6.4 高亮:让用户“看得见命中在哪里”(无需额外代码) #
Easy-Es 的高亮由实体字段上的 @HighLight 驱动。
你不需要额外写 wrapper.highLight(...) 之类的逻辑,只要正常 match 查询,返回结果里的 highlightMessage 会自动填充。
举例:
- 搜索词:
超时 - message:
请求超时,已触发重试 - highlightMessage:
请求 <em>超时</em>,已触发重试
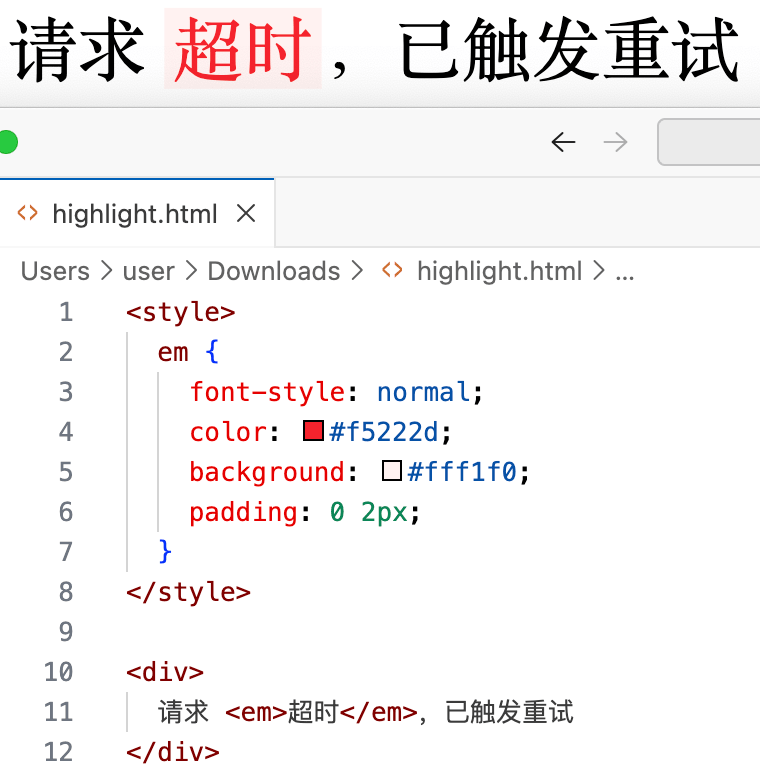
图2:高亮效果示意
6.5 聚合:按级别、按服务做分桶统计(告警质量分析必备) #
@Service
@RequiredArgsConstructor
public class AlarmLogAggService {
private final AlarmLogMapper alarmLogMapper;
public Aggregations aggByLevelAndService(Long start, Long end) {
LambdaEsQueryWrapper<AlarmLog> wrapper = new LambdaEsQueryWrapper<>();
if (start != null) {
wrapper.ge(AlarmLog::getTimestamp, start);
}
if (end != null) {
wrapper.le(AlarmLog::getTimestamp, end);
}
wrapper.groupBy(false, AlarmLog::getLevel, AlarmLog::getService);
SearchResponse response = alarmLogMapper.search(wrapper);
return response.getAggregations();
}
}
聚合落地场景 #
- 日报/周报:按 level 分桶
- 服务健康度:按 service TopN
- 告警质量:ERROR 占比、告警来源分布
7. SQL 查询能力:适用场景 + 风险边界(可选但很实用) #
Easy-Es for Easysearch 提供 executeSQL(String sql) 入口,适合作为轻量分析与快速验证通道。
但必须强调:
SQL 入口如果不收口,会非常容易变成“任意查询通道”,带来安全与性能风险。
7.1 推荐的使用方式(示意) #
@Service
@RequiredArgsConstructor
public class AlarmLogSqlService {
private final AlarmLogMapper alarmLogMapper;
private static final Set<String> LEVEL_WHITELIST = Set.of("INFO", "WARN", "ERROR");
public String queryBySql(String level) {
String sql = "SELECT * FROM dev_alarm_log LIMIT 10";
if (StringUtils.hasText(level)) {
String upper = level.trim().toUpperCase();
if (!LEVEL_WHITELIST.contains(upper)) {
throw new IllegalArgumentException("invalid level");
}
sql = "SELECT * FROM dev_alarm_log WHERE level = '" + upper + "' LIMIT 10";
}
return alarmLogMapper.executeSQL(sql);
}
}
7.2 SQL 入口生产必做清单 #
- 必须鉴权(建议网关层 + 服务层双保险)
- 必须审计(记录 SQL、用户、时间、耗时)
- 参数必须白名单(不要放开任意字段)
- 限制 LIMIT 上限、超时、频率
- 不要把 SQL 当成高并发业务接口
8. 生产最佳实践 Checklist #
8.1 索引命名与多环境隔离 #
- 用
index-prefix区分环境:dev_ / test_ / prod_ - 日志类索引建议按时间滚动(按天/月)
- 配合生命周期管理:冷热分离、快照、归档
8.2 自动索引托管:选对策略 #
smoothly适合开发/迭代期:减少手工迁移与停机- 生产期 Mapping 变更仍需流程:
- 评审
- 灰度
- 回滚预案
- 字段类型变更属于高风险操作:优先兼容设计
8.3 写入与刷新策略:不要为了“实时”牺牲吞吐 #
- immediate:强实时,写入成本高
- wait_until:更温和,适合日志/告警
- 大吞吐写入建议配合:
- 批量写
- 异步写入
- Kafka 削峰
8.4 查询性能:避免深分页 #
- 常规分页:from + size 可用
- 深分页:优先 search_after
- scroll 适合导出类任务(注意资源释放)
8.5 安全与合规 #
- 生产启用 https + security:账号、权限、审计
- SQL 入口与调试接口必须鉴权与限流
- 网关统一流量入口与防护(鉴权、限流、WAF)
9. 你将收获什么? #
通过 Easy-Es 深度集成 Easysearch,你可以把“写搜索”从 DSL 工程体力活升级为:
- ORM 化:CRUD / Query / HighLight / Agg / SQL 更像写数据库
- 工程化:索引创建、更新、迁移由框架托管,减少人为失误
- 迁移友好:底层引擎替换更平滑,应用改造更少
- 生产可控:通过最佳实践与边界约束,避免把搜索当数据库用
参考链接 #
- Easysearch 官网: https://www.infinilabs.cn/products/easysearch/
- Easy-Es项目仓库(Dromara): https://gitee.com/dromara/easy-es 和 https://github.com/dromara/easy-es
- Easy-Es 2.1.0-easysearch 发布说明(含依赖与配置示例):
https://infinilabs.cn/blog/2025/easy-es-2.1.0-easysearch-release/ - Easysearch Java Client 文档:
https://docs.infinilabs.com/easysearch/main/docs/references/client/java-client/

