
















用户数量的增长都可能拉低应用程序的性能。因此,应用程序可能要求从数据库体系迁移到搜索架构体系,比如 Elasticsearch、 Easysearch。
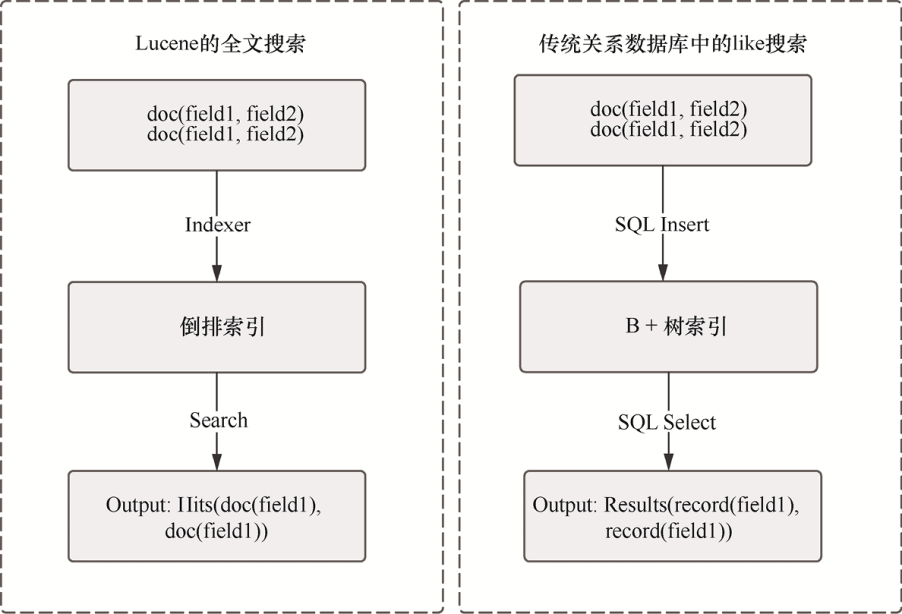
Lucene 是一种全文搜索引擎,它与传统关系数据库的本质差异在于它们的底层数据结构不同。Lucene 的底层数据结构是倒排索引结构,而传统关系数据库的底层数据结构通常是** B 树或 B+ 树组织的正向聚集索引和非聚集索引结构**。
正排索引 vs 倒排索引 #
正排索引展现的是从文档编号(docID)到文档内容、文档字段的关联关系。
| docID | 文档内容 |
|---|---|
| doc1 | “8 Oranges” |
| doc2 | “2 Blueberries” |
| doc3 | “5 Cherries” |
倒排索引展现的是文档中的分词(Term)到 docID 的映射关系。
| 分词 (Term) | docID 列表 |
|---|---|
| “Oranges” | doc1 |
| “Blueberries” | doc2 |
| “Cherries” | doc3 |
根据查询语句与文档内容的相似度,Lucene 匹配算法将匹配程度高的结果排列在前面返回。而传统关系数据库中通常没有类似的默认匹配算法。
传统关系数据库引擎由于使用 B 树、B+ 树维护索引数据结构,索引的更新会导致大量的输入输出(Input/Output, I/O)开销。在 Lucene 中,改进策略包含对索引段的单次(Write-Once)提交。当需要添加新的文档时,Lucene 会不断地创建新的索引段,然后后台线程定期将小的索引段合并成一个大的段,从而在不影响检索效率的前提下提高索引的效率。
Lucene 的全文搜索机制 #
Lucene 全文搜索机制首先对文档进行分词,然后对分词构建倒排索引。Lucene 的 API(应用程序接口)设计相对通用,看起来类似传统关系数据库的层次结构:表、记录和域字段。Lucene 的数据按照层次组织起来并体现数据之间的隶属关系。传统的数据库可以相对容易地映射到 Lucene 接口的存储空间。
1. Lucene 的全文搜索 #
大多数全文搜索引擎都使用倒排索引,比如将一个分词用作哈希的键,而对应的键值是与该键关联的文档集。
假设有文档集合 doc set 和分词集合 term set 如下:
doc set = {d1, d2, d3, ..., dn} term set = {t1, t2, t3, ..., tn}
可以通过倒排索引形成一个分词与文档的对应矩阵如下:
t1->{d1, d3, d6, ..., dn}t2->{d13, d50, d4, ..., dn}t3->{d13, d47, d34, ..., dn}- …
tn->{d30, d27, d17, ..., dn}
当请求返回包含分词 t1 的所有文档集时,文档集 {d1, d3, d6, ..., dn} 被直接返回。
2. 传统关系数据库中的 LIKE 搜索 #
LIKE 用于在关系数据库的任何字符串字段中搜索字符串。当使用 LIKE 运算符搜索时,数据库会扫描表中的每一行以进行比较,然后丢弃不符合条件的行。
整个过程将使用大量的内存空间和时间进行比较查询,因此 LIKE 搜索只适用于行数较少的数据表。而对于 Lucene 的全文搜索,搜索发生在倒排索引表中,它使用较少的资源即可高效执行查询。
倒排索引的使用场景 #
当应用属于 **重连接(Join-Heavy)**的场景时,应使用传统关系数据库。相反,若业务场景需要支持大量全文搜索,建议选择 Lucene 搜索引擎。
归根结底,Lucene 与传统关系数据库的差异来源于其索引结构。索引本身有很多类型,比如 B 树、哈希表、倒排索引。为了实现不同的目的,必须选择正确的索引。Lucene 选择倒排索引结构的主要目的就是支持快速高效的全文搜索。
下面列举一些使用 Lucene 或倒排索引的典型场景:
(1) 社交软件 #
很多国内著名的社交与内容平台都部署了 Lucene 或类似的全文检索技术,例如:
- 微博:使用 Lucene/Elasticsearch 体系支持海量微博动态的实时搜索与热点话题挖掘,应对极高的并发查询请求。
- 知乎:利用全文检索技术支持亿级问答内容、文章的快速检索与个性化推荐,确保用户能精准获取知识信息。
(2) 域名系统 #
域名系统(DNS)同时支持正排索引结构和倒排索引结构。
- 正排索引结构:输入主机名,搜索正向数据结构并返回 IP 地址。
- 倒排索引结构:输入 IP 地址,搜索反向数据结构并给出主机名。
(3) 程序化广告系统 #
程序化广告系统也同时使用正排索引和倒排索引结构,因为广告商需要精确定位广告受众,这样设计可以提升广告投放效果。程序化广告系统通常使用布尔逻辑表达式来准确描绘目标受众,例如:
age ∈ {20-35} ∩ region ∈ {BJ, SH} ∩ net ∈ {Wi-Fi} ∩ app ∈ {3501}
假定上述众多属性代表的用户画像存储在传统关系数据库的一张宽表中。为了支持复杂的查询条件,需要对宽表中几乎每个字段建立索引。这种方案简单但缺乏扩展性。
当数据量较小且需要灵活组合任意字段来进行检索时,将数据全部加载到内存并构建检索数据结构是一种简单而有效的思路。但在一些复杂的广告业务场景下,传统关系数据库往往不能满足任意字段随意组合的高效查询需求。相反,Lucene 引擎的倒排索引的强项就是支持布尔查询和灵活检索。
小结 #
本文深入探讨了 Lucene 全文搜索引擎与传统关系数据库(RDBMS)在底层数据结构、搜索机制及适用场景上的核心差异。通过对比倒排索引与 B+ 树结构,解析了 Lucene 在大数据量全文检索下的性能优势。

