
















对于在单个文件中查找某个单词或短语,这并不是一件复杂的事情。例如,grep 这样的文本搜索工具,在处理少量、结构简单的文本文件时已经足够高效。
但问题在于:
当数据规模上升到“海量”级别时,情况就完全不同了。
在现实世界中,各行各业每天都会产生难以想象的数据量,例如:
- 百度 每秒要处理数万次搜索请求
- 抖音 每分钟会有上百万个视频被上传
- 程序化广告系统每天产生数百亿条广告日志记录
仅仅“收集和存储”这些数据本身并没有太大价值。
真正的价值在于:是否能够从海量数据中快速提取有用信息,并将其转化为业务决策或商业收益。
而实现这一目标的核心基础设施,正是 搜索引擎。
搜索引擎的核心组成 #
从系统架构角度来看,一个完整的搜索引擎通常由以下四个核心子系统构成:
1. 爬虫子系统(Crawler) #
爬虫子系统负责从数据源中采集数据。
- 在互联网搜索场景中,爬虫通常以 URL(Uniform Resource Locator)为入口
- 通过 BFS(广度优先搜索) 或 DFS(深度优先搜索) 不断扩展新的链接
- 在抓取内容的同时,保存页面的元数据(如 URL、标题、时间戳等)
在企业搜索或日志搜索场景中,爬虫的角色往往由日志采集器、数据同步程序等组件承担。
2. 索引子系统(Indexing) #
索引子系统负责对原始数据进行解析,并构建高效的数据结构,以支持快速检索。
常见的索引方式包括:
- 正排索引(Forward Index)
以文档为中心,记录每个文档包含哪些词项 - 倒排索引(Inverted Index)
以词项为中心,记录每个词项出现在哪些文档中
索引结构的设计,直接决定了搜索系统在性能和扩展性上的上限。
3. 检索子系统(Search / Retrieval) #
检索子系统负责处理用户查询请求:
- 将用户输入的查询字符串解析为内部的查询对象(Query)
- 在索引结构中执行查找
- 返回与查询条件匹配的候选文档集合
这一阶段通常被称为 “初筛”,目标是快速缩小搜索范围。
4. 排名子系统(Ranking) #
在检索子系统返回候选结果之后,排名子系统会:
- 基于文档相关性、权重、统计特征等信息
- 对结果进行评分和排序
- 最终返回符合用户期望的搜索结果列表
正排索引与倒排索引的直观理解 #
可以通过“图书”这个熟悉的例子来理解正排索引与倒排索引的区别:
- 图书目录
按章节列出内容及对应页码
👉 类似于 正排索引 - 图书索引页
按关键词列出其在书中出现的页码
👉 类似于 倒排索引
在搜索引擎中,倒排索引是实现高性能全文检索的核心数据结构。
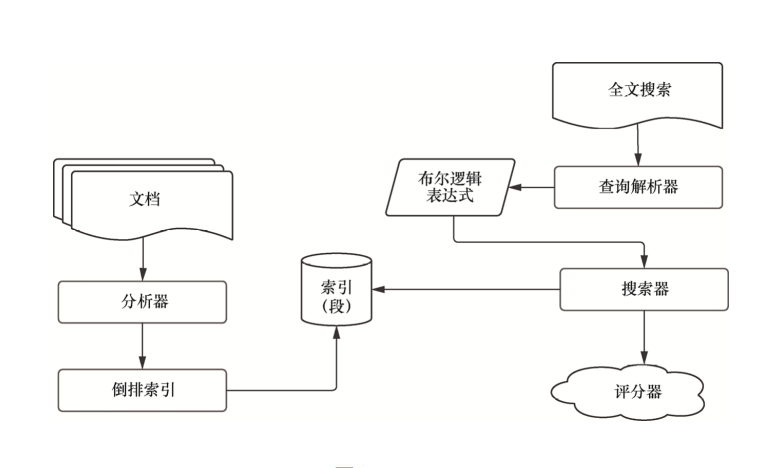
Lucene:搜索引擎的核心基础库 #
Lucene 是一个提供索引和搜索能力的高性能搜索库,也是 Elasticsearch、OpenSearch、Easysearch 等搜索引擎的底层技术基础。
它并不是一个完整的搜索系统,而是为搜索系统提供关键能力的“引擎内核”。
Lucene 中一些关键组件包括:
1. 全文搜索(Full-Text Search) #
Lucene 不仅支持基于文档标题的搜索,还支持基于文档内容的全文检索。
它通过分析文档中的所有词项,并在倒排索引中进行匹配,从而返回与查询条件最相关的文档。
2. 分析器(Analyzer) #
分析器用于将原始字符串转换为可以写入倒排索引的 词项(Token),通常包括:
- 分词(Tokenization)
- 大小写转换
- 停用词过滤
- 同义词扩展等
分析器的设计直接影响搜索结果的准确性和召回率。
3. 倒排索引(Inverted Index) #
分析器生成的词项会被索引模块组织成倒排索引结构。
倒排索引以词项为核心,记录每个词项出现在哪些文档中,是 Lucene 高性能检索能力的基础。
4. 查询解析器(Query Parser) #
查询解析器用于将人类可读的查询字符串,解析为 Lucene 内部可执行的查询对象。
它支持丰富的查询表达方式,例如:
- 关键词查询
- 短语查询
- 范围查询
- 组合条件查询
5. 布尔表达式(Boolean Expression) #
Lucene 支持通过布尔逻辑表达式构建复杂查询条件,例如:
ANDORNOT
这使得用户能够构建语义更加精确、结构更加复杂的查询。
6. 搜索器(Searcher) #
搜索器负责在倒排索引中执行查询,并返回匹配的文档结果。
它支持多种查询类型,包括:
- 短语查询
- 模糊查询
- 范围查询等
7. 评分器(Scoring) #
评分器用于计算文档与查询条件之间的相关度,并根据评分结果对文档进行排序。
Lucene 内部实现了多种相关性评分模型,为搜索结果排序提供了坚实基础。
小结 #
从简单的文本搜索工具,到支撑海量数据检索的分布式搜索引擎,其核心能力始终围绕着 索引、检索与排序 展开。
Lucene 作为搜索引擎领域的事实标准,为上层搜索系统提供了成熟、稳定且高性能的基础能力。理解 Lucene 的基本架构与核心组件,是理解 Elasticsearch、OpenSearch、 Easysearch 等搜索引擎产品的前提。

