
















当我们在搜索框中输入“Easysearch 快速入门”,然后按下回车,零点几秒后,相关的文档列表便呈现在眼前。这个过程看似简单,但背后却是一套精密、高效的分布式协作系统在运转。
它不是简单地遍历每一篇文档去寻找关键词。相反,它像一位经验丰富的图书管理员,能瞬间从亿万册藏书中,不仅找到相关的书籍,还能按照与你需求的匹配度排好序。
今天,我们就将跟随一个搜索请求,开启一场深入 Easysearch 内部的奇妙旅程,揭开搜索引擎“快”与“准”的秘密。
序章:一切的基石——倒排索引 #
在旅程开始前,我们必须了解 Easysearch 最核心的“藏宝图”——倒排索引 (Inverted Index)。
想象一下一本厚厚的书,如果没有书末的“索引表”,要找到某个概念,你只能一页一页地翻。而索引表的作用,就是将“概念”(关键词)直接映射到它出现的“页码”(文档 ID)。
倒排索引就是这个原理:
- 正向索引(我们通常的认知):
文档 ID -> 文档内容 - 倒排索引(搜索引擎的核心):
关键词 -> 出现该词的文档 ID 列表
例如:
{
"Easysearch": [Doc1, Doc5, Doc42],
"快速": [Doc5, Doc99],
"入门": [Doc1, Doc5, Doc101]
}
有了这张图,当我们要搜“Easysearch 快速”时,就不再需要扫描所有文档,而是直接取出两个关键词的文档列表 [1, 5, 42] 和 [5, 99],然后求它们的交集 [5]。瞧,我们瞬间就定位到了 Doc5。
这就是搜索引擎快如闪电的根本原因。
第一站:兵分多路——分散-聚合(Scatter-Gather) #
我们的查询请求 GET /_search?q=Easysearch 首先抵达集群中的一个协调节点 (Coordinating Node)。
由于 Easysearch 是一个分布式系统,数据被分散存储在多个分片 (Shard) 上。协调节点就像一位总指挥,它自己不负责具体的搜寻工作,而是将任务分派下去。这个总战略就是——分散-聚合 (Scatter-Gather)。
- 分散 (Scatter):总指挥将搜索请求,像广播一样,同时发送给所有相关的分片。
- 聚合 (Gather):等待所有分片都返回结果后,总指挥将这些零散的结果汇总、排序,最终形成完整的全局结果。
这个战略被拆解为两个核心阶段来执行:查询阶段和取数阶段。
第二站:查询阶段(Query Phase)——只找ID,不拿正文 #
这是“分散”阶段的核心。协调节点的目标是:用最小的代价,找出全局最匹配的前 N 个文档的 ID 是什么。
比喻: 总指挥派侦察兵去各个战区,命令他们:“不要带回任何战利品,只需要告诉我每个战区最有价值的 10 个目标的坐标和价值评估!”
这个阶段在每个分片上,会发生以下事情:
- 查询解析:将用户的查询字符串(如 “Easysearch 快速入门”)进行分词,得到
[easysearch, 快速, 入门]这几个关键词。 - 查找倒排:拿着这些关键词,去倒排索引中找到各自的文档列表。
- 布尔计算:根据查询逻辑(是 AND 还是 OR),对文档列表进行交集或并集运算,得到一个匹配文档的集合。
- 相关性打分 (Scoring):这是搜索的灵魂!对于每一个匹配的文档,Easysearch 会使用 BM25 算法计算一个相关性分数。这个分数会考虑:
- 词频 (Term Frequency):关键词在文档中出现的次数。
- 逆文档频率 (Inverse Document Frequency):关键词在所有文档中出现的频率(越稀有的词,权重越高)。
- 字段长度:关键词出现在短标题里,比出现在长篇大论的正文里,相关性更高。
- 本地排序:每个分片都维护着一个优先队列(小顶堆),它会根据算分结果,将自己分片内“最相关”的前 N 个结果(例如 Top 10)筛选出来。
- 返回简报:最后,每个分片只将这 Top 10 的
(文档ID, 分数)列表返回给协调节点。
重点: 在这个阶段,网络中传输的数据量极小,只有文档 ID 和分数,没有任何文档的原文(_source),这极大地提升了效率。
第三站:中场汇总(Merge Phase)——全局排序 #
现在,协调节点收到了来自所有分片的“侦察兵简报”。比如有 5 个分片,每个分片都返回了 Top 10 的结果,那么协调节点现在手上就有了 50 个候选文档。
它的任务很简单:对这 50 个候选文档,按照分数进行一次全局排序,选出最终的全局 Top 10。
经过这一步,协调节点终于知道了:“好的,这次查询,全宇宙最匹配的 10 篇文档的 ID 分别是 [Doc5, Doc42, Doc99, ...]”。
第四站:取数阶段(Fetch Phase)——按图索骥,拿回原文 #
现在,我们已经有了最终的“藏宝图”(全局 Top 10 的文档 ID 列表),是时候去取回宝藏了。
- 精准分发:协调节点会看一下这 10 个 ID 分别属于哪个分片(比如 Doc5 在分片1,Doc42 在分片3),然后向对应的分片发送一个“取货”请求。这通常是一个 Multi-GET 操作。
- 提取原文:收到取货命令的分片,会根据文档 ID,直接从磁盘的正排索引(Stored Fields)中读取文档的原始 JSON (
_source)。 - 高亮处理:如果用户请求了高亮,分片会在此阶段对
_source内容进行分析,为匹配的关键词加上<em>标签。 - 返回正文:分片将完整的文档内容返回给协调节点。
- 最终拼装:协调节点将所有取回的文档原文拼装成最终的 JSON 响应,返回给客户端。
至此,一个查询的旅程宣告结束。
总结:一次查询,两次网络往返 #
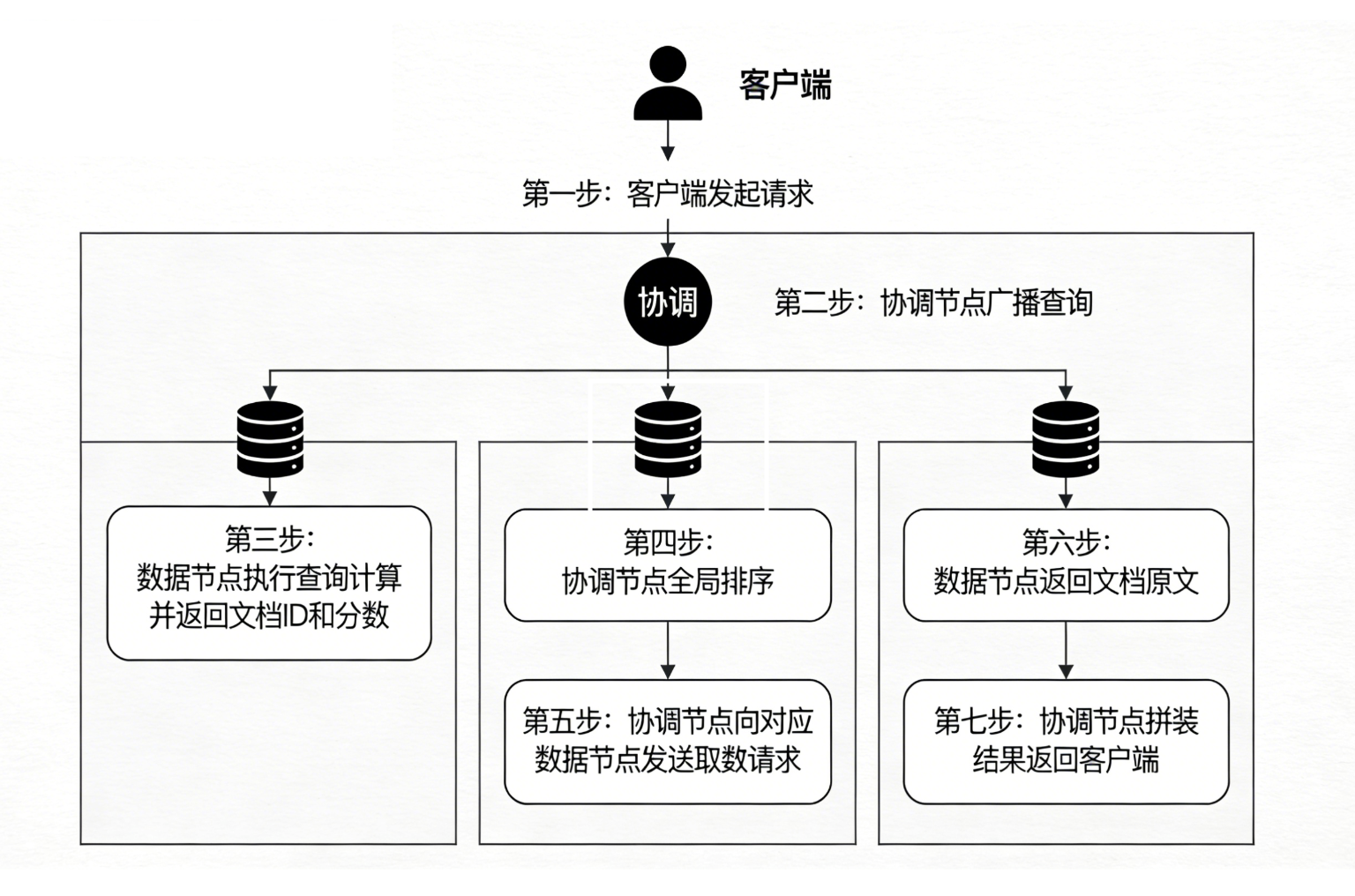
回顾整个流程,我们可以看到 Easysearch 将一次复杂的分布式搜索,拆解成了两次清晰的网络交互:__
- 第一次(Query Phase):一次广播,多次轻量级返回。目的是用最小的成本确定全局最优的文档 ID。
- 第二次(Fetch Phase):多次点对点请求,多次重量级返回。目的是精准地获取用户最终需要看到的文档内容。
这种 Query-Then-Fetch 的模型,是所有分布式搜索引擎的核心思想。它通过分而治之、两阶段处理的方式,巧妙地平衡了计算开销和网络开销,确保了即使在 TB 甚至 PB 级别的海量数据面前,依然能提供毫秒级的查询响应。
下一次,当你享受秒级搜索的快感时,不妨回想一下,你发出的那个小小请求,正在 Easysearch 的世界里经历着怎样一场精密而高效的旅程。

