
















在人工智能快速发展的今天,用户对搜索系统的期待早已超越了“输入关键词、返回文档”的简单模式。越来越多的业务场景中,用户希望用一张图、一段语音、一句话,甚至多种信息组合的方式进行查询——这正是 **多模态搜索(Multimodal Search)**的核心能力。
作为面向企业级应用的分布式搜索型数据库,Easysearch 不仅支持传统的全文检索和结构化查询,还深度融合了多模态语义理解能力,帮助企业在图像、文本、语音等多种数据之间实现跨模态关联与智能检索。
本文将从原理、场景到技术实现,全面解析 Easysearch 如何构建高效、可落地的多模态搜索体系。
一、什么是多模态搜索? #
1.1 传统搜索的局限 #
传统搜索引擎主要处理的是文本数据。例如,用户输入“黑色卫衣”,系统会匹配包含这些关键词的商品描述或网页内容。
但现实中的信息远不止文字:
- 用户上传一张街拍照片,想找同款衣服
- 客服收到一段语音留言:“我昨天下的订单还没发货”
- 运维人员看到一条日志截图,想查找类似故障记录
这些都不是纯文本问题,而是涉及图像、语音、文本等多类型数据的综合理解需求。传统搜索对此无能为力。
1.2 多模态搜索的基本思想 #
多模态搜索的本质是:
将不同形式的数据(如图片、语音、文本)统一映射到同一个“语义空间”中,通过向量表示实现跨模态相似性计算。
通俗地说:
- 图像被转换成一个数字向量(embedding)
- 文本也被转换成一个数字向量
- 如果它们表达的意思相近(比如“一只黑猫趴在窗台” 和 一张黑猫照片),那么这两个向量在空间中就会靠得很近
- 搜索时,无论你输入的是图还是文字,系统都能找到语义最接近的结果
这种能力让搜索真正具备了“理解力”。
二、典型应用场景 #
2.1 图像搜商品(以图搜货) #
电商平台中,用户上传一张穿搭照片,系统自动推荐外观相似的商品。这是典型的“图像→文本/商品”搜索。
2.2 语音工单自动归类 #
客服中心接收大量语音留言,系统将其转为语义向量后,自动匹配历史相似案例,提升响应效率。
2.3 跨模态知识检索 #
企业内部存在大量非结构化数据:会议截图、PPT 扫描件、录音纪要等。员工可通过自然语言提问(如“上次讨论预算的会议说了什么?”),系统结合图像OCR+语音识别+文本向量化,返回相关片段。
2.4 日志与告警图文关联分析 #
当监控系统产生一张异常图表时,运维人员可用该图搜索历史相似事件报告,辅助根因定位。
三、Easysearch 中的多模态搜索实现 #
Easysearch 基于统一的向量检索架构,支持将多种模态数据编码为高维向量,并在同一索引中进行混合查询。其核心流程如下:
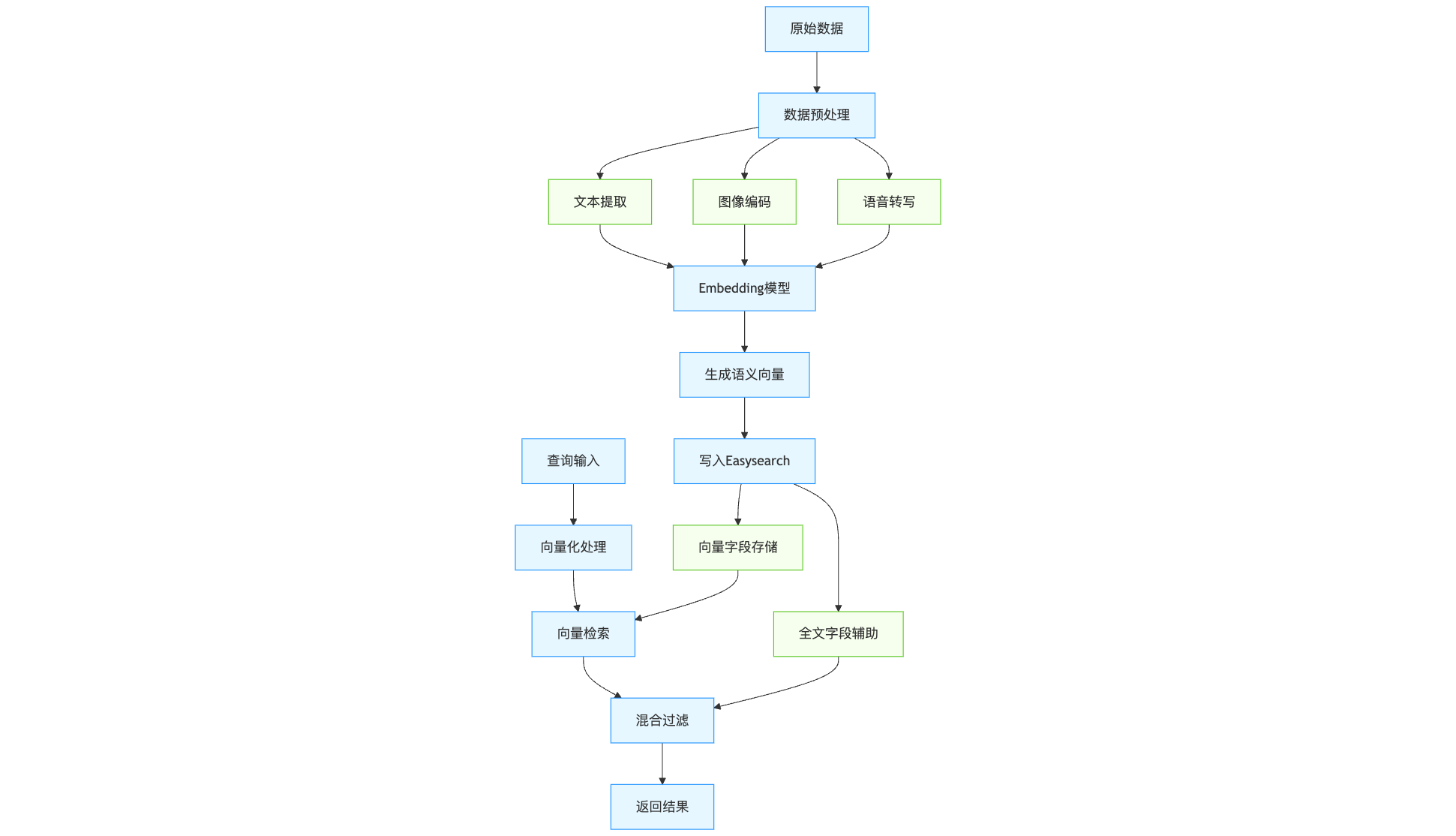
下面我们详细介绍关键环节。
3.1 数据预处理与向量生成 #
在多模态搜索中,不同类型的数据(文本、图片、音频等)需要被转换为一种可统一计算相似度的表示形式。
这一表示形式通常就是 语义向量(Embedding)。
Easysearch 并不强制绑定某一种模型,而是通过插件化机制,将向量生成能力解耦出来,使其既灵活又易于集成。
3.1.1 向量生成方式概览 #
在写入 Easysearch 之前,原始数据需要先被转换为向量。
这一过程通常由 外部 AI 模型 完成,Easysearch 负责向量的存储、索引和检索。
目前 Easysearch 支持:
- OpenAI API 兼容的 Embedding 接口
- Ollama Embedding 接口
使用前需安装:
knn插件(向量索引与检索)ai插件(Embedding 与 AI 接口集成)
这种设计使 Easysearch 专注于搜索与检索本身,而不会与具体模型强绑定,符合企业级系统对稳定性与可维护性的要求。
3.1.2 创建包含向量字段的索引 #
在 Easysearch 中,向量通过专用字段类型进行存储。
下面示例创建了一个支持多模态数据的索引,其中:
text_vector:用于存储语义向量title:用于传统全文检索source_type:标识数据来源(文本 / 图片 / 音频)
PUT /multimodal-index
{
"mappings": {
"properties": {
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 768,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
},
"input_text": {
"type": "text"
},
"title": {
"type": "text"
},
"source_type": {
"type": "keyword"
}
}
}
}
这里的几个关键点:
dims表示向量维度,需要与 embedding 模型输出一致similarity指定向量相似度计算方式(如余弦相似度)knn参数用于控制向量索引结构和检索性能
3.1.3 文本写入时自动生成向量 #
对于纯文本场景,Easysearch 支持在写入阶段直接完成向量生成,无需在业务侧提前调用模型。
这通过 Ingest Pipeline(写入管道) 来实现。
创建文本向量生成管道 #
下面的管道使用 text_embedding 处理器,在写入时自动调用 embedding 接口,将文本转为向量并写入指定字段:
PUT _ingest/pipeline/text-embedding-pipeline
{
"description": "用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://api.openai.com/v1/embeddings",
"vendor": "openai",
"api_key": "<api_key>",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-3-small",
"dims": 768,
"ignore_missing": false,
"ignore_failure": false
}
}
]
}
该管道的作用可以概括为一句话:
“把用户写入的自然语言文本,自动转成可用于向量检索的语义表示。”
3.1.4 使用管道进行批量写入 #
text_embedding 处理器在使用方式上与其他 Ingest 处理器完全一致,可无缝集成到批量写入流程中:
POST /_bulk?pipeline=text-embedding-pipeline&pretty&refresh=wait_for
{ "index": { "_index": "multimodal-index" } }
{ "input_text": "图片,视频,pdf 转化后特征值", "source_type": "image", title:"时尚卫衣xxx" }
{ "index": { "_index": "multimodal-index" } }
{ "input_text": "这是另一示例文本。","source_type": "text", title:"多模态搜索应用实践" }
3.2 多模态查询流程 #
假设用户上传一张产品图,希望查找相关文档说明。
步骤 1:客户端或前置服务调用图像模型生成向量 #
# 使用 CLIP 模型将图像转为向量
vector = clip_model.encode(image_path)
步骤 2:发送向量检索请求至 Easysearch #
GET /multimodal-index/_search
{
"query": {
"knn_nearest_neighbors": {
"field": "text_vector",
"vec": {
"values": [
-0.37436,
-0.11959,
-0.87609,
-1.1217,
1.2788,
0.48323,
-0.53903,
0.053659,
-0.23929,
-0.12414,
......
]
},
"model": "lsh",
"similarity": "cosine",
"candidates": 50
}
},
"fields": ["title", "source_type"]
}
步骤 3:返回语义最相似的文档(可能是文本、PDF、另一张图) #
结果中可能包括:
- 一篇标题为《XX型号使用手册》的 PDF 文档
- 一段介绍该产品的视频字幕文本
- 另一张角度不同的产品图
所有结果都与输入图像在语义上高度相关,尽管它们的数据形态完全不同。
3.3 混合查询:语义理解与结构化条件的协同 #
在真实业务场景中,仅依赖语义相似度进行搜索往往是不够的。
纯语义检索擅长理解“意思相近”,但它并不了解业务背景。例如:
- 是否只搜索某一类文档
- 是否限定发布时间范围
- 是否需要排除无效或历史数据
因此,企业级搜索系统通常需要将 语义理解能力 与 结构化条件过滤 结合使用,才能在“找得全”和“找得准”之间取得平衡。
Easysearch 正是通过 混合查询(Hybrid Query) 来实现这一目标。
3.3.1 业务问题示例 #
假设我们希望实现如下查询需求:
查找最近一周内发布的、与某张图片(或描述)语义相似的技术文档
这个需求中,实际包含了三类不同的约束:
- 业务类型约束:仅限技术文档
- 时间范围约束:最近 7 天内发布
- 语义相似度约束:内容与给定描述在语义上接近
Easysearch 允许将这些约束统一表达在一次查询中执行。
3.3.2 通过搜索管道注入语义能力 #
在混合搜索中,向量查询通常需要在查询阶段动态生成向量。
Easysearch 通过 Search Pipeline(搜索管道) 完成这一过程。
下面示例创建了一个搜索管道,用于在查询阶段调用阿里云的 embedding 服务,将自然语言查询自动转为向量:
PUT /_search/pipeline/search_model_aliyun
{
"rewrite_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "aliyun search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "<api_key>",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}
该管道的作用可以理解为:
在搜索请求进入执行阶段前,自动补齐语义向量信息。
3.3.3 设置默认搜索管道 #
为了避免每次查询都显式指定管道,可以将其设置为索引的默认搜索管道:
PUT /multimodal-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}
这样,所有针对该索引的搜索请求,都会自动具备语义理解能力。
3.3.4 执行混合搜索查询 #
在完成上述配置后,即可使用 Hybrid Query 将结构化条件与语义搜索组合在一起:
GET /multimodal-index/_search
{
"_source": {
"exclude": ["text_vector"]
},
"query": {
"hybrid": {
"queries": [
{ "term": { "type": "technical_manual" } },
{ "range": { "publish_time": { "gte": "now-7d" } } },
{
"semantic": {
"text_vector": {
"query_text": "黑色卫衣",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
]
}
}
}
从查询结构可以清晰看到:
term和range用于业务规则过滤semantic用于语义相似度召回- 多种查询条件在一次请求中协同执行
四、工程优势与设计哲学 #
Easysearch 的多模态搜索并非追求炫技,而是围绕“可控、可组合、可落地”三大原则设计:
- 模块化架构:向量能力作为插件式组件,不影响原有全文检索体系
- 开放集成:兼容主流 embedding 模型和服务,支持公有云或私有部署
- 统一查询语言:仍使用标准 DSL,开发者无需学习新语法
- 性能保障:基于 LSH 等近似最近邻算法,支持亿级向量高效检索
更重要的是,Easysearch 强调“多模态能力服务于业务”,而非替代传统搜索。它允许企业根据场景灵活选择:
- 纯文本检索
- 纯向量检索
- 混合检索
从而在准确性、速度和成本之间取得最佳平衡。
五、总结 #
多模态搜索正在成为企业智能化升级的关键基础设施。Easysearch 通过统一的向量检索引擎,打通文本、图像、语音等异构数据之间的语义壁垒,使搜索系统真正具备“跨模态理解”能力。
其核心价值在于:
- ✅ 支持多种数据类型的语义统一表达
- ✅ 提供标准化 API 与 DSL,易于集成
- ✅ 结合结构化过滤,实现精准召回
- ✅ 面向企业级场景,强调稳定性与可维护性
无论是电商、金融、制造还是 IT 运维,只要存在多样化数据源和复杂查询需求,Easysearch 的多模态搜索都能提供坚实的技术支撑。
未来,随着大模型与向量数据库的深度融合,我们期待看到更多“用一张图提问、用一句话解决问题”的智能搜索体验在 Easysearch 上落地生根。
📚 参考资料:

