
















1. 什么是 Easysearch? #
Easysearch 是一款现代分布式搜索与分析引擎,支持全文检索、结构化检索、聚合分析等能力。它能够处理大规模文档数据,通过灵活的搜索与统计能力帮助开发者构建实时分析、报表展示、业务监控等功能。Easysearch 的聚合功能设计来源于 Elasticsearch 的 Aggregations 框架,可实现高效的数据统计与分组分析。
2. 聚合的基本概念 #
在 Easysearch 中,聚合(Aggregations)是一种能够将数据按照某种规则进行统计与组合的能力。聚合通常不返回具体的匹配文档,而是返回统计结果或分组信息。聚合主要分为:
- Bucket(桶)聚合:将符合条件的文档分成多个“桶(Bucket)”,类似 SQL 中的
GROUP BY。 - Metric(指标)聚合:对一组文档或桶进行数值计算,如求平均值、总和等。
一个聚合请求典型结构如下:
GET /your_index/_search
{
"size": 0,
"aggs": {
"your_aggregation_name": {
"AGG_TYPE": {
...
}
}
}
}
其中 "size": 0 表示不返回具体文档,只关心聚合结果。
3. 桶聚合:按值分组(terms) #
Bucket 聚合 就是“分桶”,比如按照某个字段的不同值将数据分成不同组,每组对应一个桶。最常用的桶聚合是 terms(词条聚合)。
3.1 terms 聚合基础
#
terms 聚合会为某个字段中出现的每个不同值建立一个桶,并统计每个桶内包含的文档数量:
GET logs/_search
{
"size": 0,
"aggs": {
"status_codes": {
"terms": {
"field": "status.keyword",
"size": 5
}
}
}
}
在这个例子中,按 status.keyword 字段的值进行分组统计,返回最频繁的 5 个状态码以及它们对应的文档计数。
解释 #
- key:每个桶对应的字段值;
- doc_count:该值对应的文档数量;
- size:限制返回多少个桶(默认有上限)。
3.2 桶聚合的意义 #
terms 聚合相当于 SQL 中的 GROUP BY 操作,它能将数据分类统计,例如:
- 按产品类别统计数量;
- 按响应码统计请求数量;
- 按用户 ID 统计用户行为分布。
结合其他聚合,还可以进一步对每个分组做数值统计。
4. 指标聚合:计算数值统计(avg / sum / min / max) #
Metric 聚合 是对符合条件的文档或某个桶内的文档进行数值计算,比如求平均值、求和等。Easysearch 支持常见的指标聚合。
4.1 常见的指标聚合类型 #
| 聚合类型 | 功能 |
|---|---|
| avg | 计算字段的平均值 |
| sum | 计算字段值的总和 |
| min | 找出字段的最小值 |
| max | 找出字段的最大值 |
这些指标类似于关系型数据库的统计函数。
4.2 avg(平均值)
#
avg 聚合返回一个字段的平均值。例如:
GET products/_search
{
"size": 0,
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
返回结果中 avg_price.value 即为该字段的平均值。
意义:可以快速获知指标中心趋势,例如平均购买金额、平均访问时间等。
4.3 sum(求和)
#
sum 聚合返回字段值的总和,例如:
GET deliveries/_search
{
"size": 0,
"aggs": {
"total_weight": {
"sum": {
"field": "weight_kg"
}
}
}
}
返回 total_weight.value 即为该字段所有文档的总和。
意义:适合用于计算总收入、总耗时等。
4.4 min / max
#
类似 sum 和 avg,min 聚合返回某字段在数据集中的最小值,max 聚合返回最大值,它们用于分析分布范围。
5. 组合聚合示例:Bucket 与 Metric 联合使用 #
指标聚合通常与桶聚合一起使用,先把文档分桶,再在每个桶内做统计。
例如,统计每个状态码的平均响应时间:
GET logs/_search
{
"size": 0,
"aggs": {
"by_status": {
"terms": {
"field": "status.keyword"
},
"aggs": {
"avg_resp_time": {
"avg": {
"field": "response_time"
}
}
}
}
}
}
执行后,每个状态码对应一个桶,并包含该状态码下的平均响应时间。
解释:
- 外层
terms聚合分组; - 内层
avg聚合在对应桶内计算平均值。
这种模式既能分类又能统计,是构建多维度分析的基础。
6. 聚合结果的可视化实践 #
Easysearch 的聚合结果本质上是结构化的 JSON 数据,这些数据非常适合直接用于可视化展示。实际应用中,我们通常遵循以下流程:
聚合查询 → 获取 buckets → 提取 key / value → 映射为图表数据
下面通过 三个最常见的场景,结合 具体聚合查询与可视化代码示例,说明 Bucket 与 Metric 聚合如何落地使用。
6.1 terms 聚合 + 柱状图:分类统计
#
场景说明 #
统计不同 状态码(status) 的请求数量,并使用柱状图展示。
① Easysearch 聚合查询 #
GET logs/_search
{
"size": 0,
"aggs": {
"status_count": {
"terms": {
"field": "status.keyword",
"size": 10
}
}
}
}
② 聚合返回结果(简化) #
{
"aggregations": {
"status_count": {
"buckets": [
{ "key": "200", "doc_count": 15230 },
{ "key": "404", "doc_count": 312 },
{ "key": "500", "doc_count": 87 }
]
}
}
}
③ 前端数据提取(JavaScript) #
const buckets = response.aggregations.status_count.buckets;
const xAxisData = buckets.map((item) => item.key);
const seriesData = buckets.map((item) => item.doc_count);
④ 使用 ECharts 渲染柱状图 #
const option = {
title: {
text: "请求状态码分布",
},
xAxis: {
type: "category",
data: xAxisData,
},
yAxis: {
type: "value",
},
series: [
{
type: "bar",
data: seriesData,
},
],
};
chart.setOption(option);
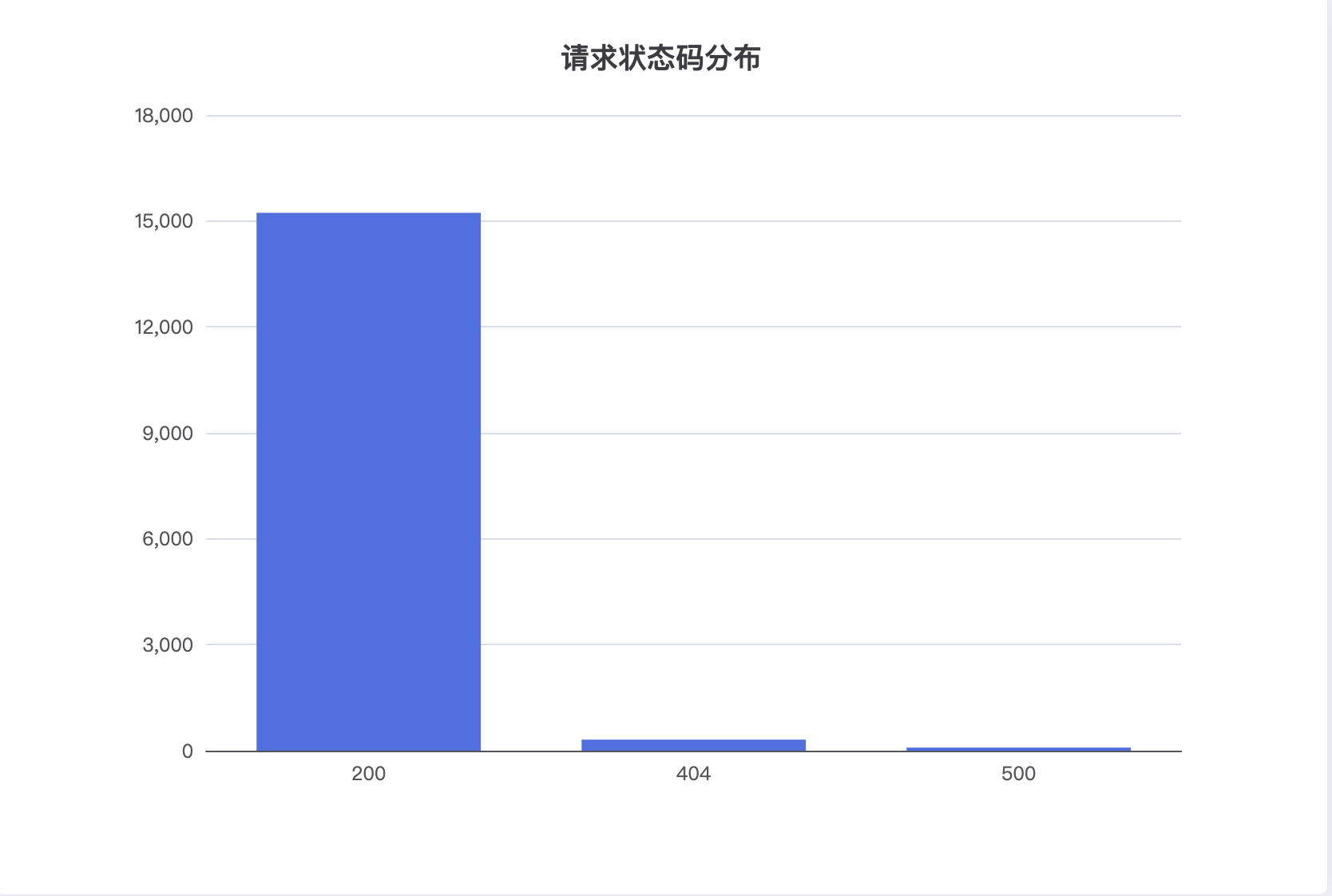
📊 效果说明
- 每个状态码对应一个柱子
- 柱子的高度即
doc_count - 非常适合做 分类统计面板
6.2 terms + avg 聚合 + 柱状图:分类指标分析
#
场景说明 #
统计 每种状态码下的平均响应时间,用于分析性能问题。
① Easysearch 聚合查询 #
GET logs/_search
{
"size": 0,
"aggs": {
"by_status": {
"terms": {
"field": "status.keyword"
},
"aggs": {
"avg_response_time": {
"avg": {
"field": "response_time"
}
}
}
}
}
}
② 返回结果(简化) #
{
"aggregations": {
"by_status": {
"buckets": [
{
"key": "200",
"doc_count": 15230,
"avg_response_time": { "value": 35.6 }
},
{
"key": "500",
"doc_count": 87,
"avg_response_time": { "value": 420.3 }
}
]
}
}
}
③ 前端数据处理 #
const buckets = response.aggregations.by_status.buckets;
const xAxisData = buckets.map((b) => b.key);
const seriesData = buckets.map((b) => b.avg_response_time.value);
④ 使用 ECharts 渲染柱状图(平均响应时间) #
const option = {
title: {
text: "不同状态码的平均响应时间",
},
xAxis: {
type: "category",
data: xAxisData,
},
yAxis: {
type: "value",
name: "ms",
},
series: [
{
type: "bar",
data: seriesData,
},
],
};
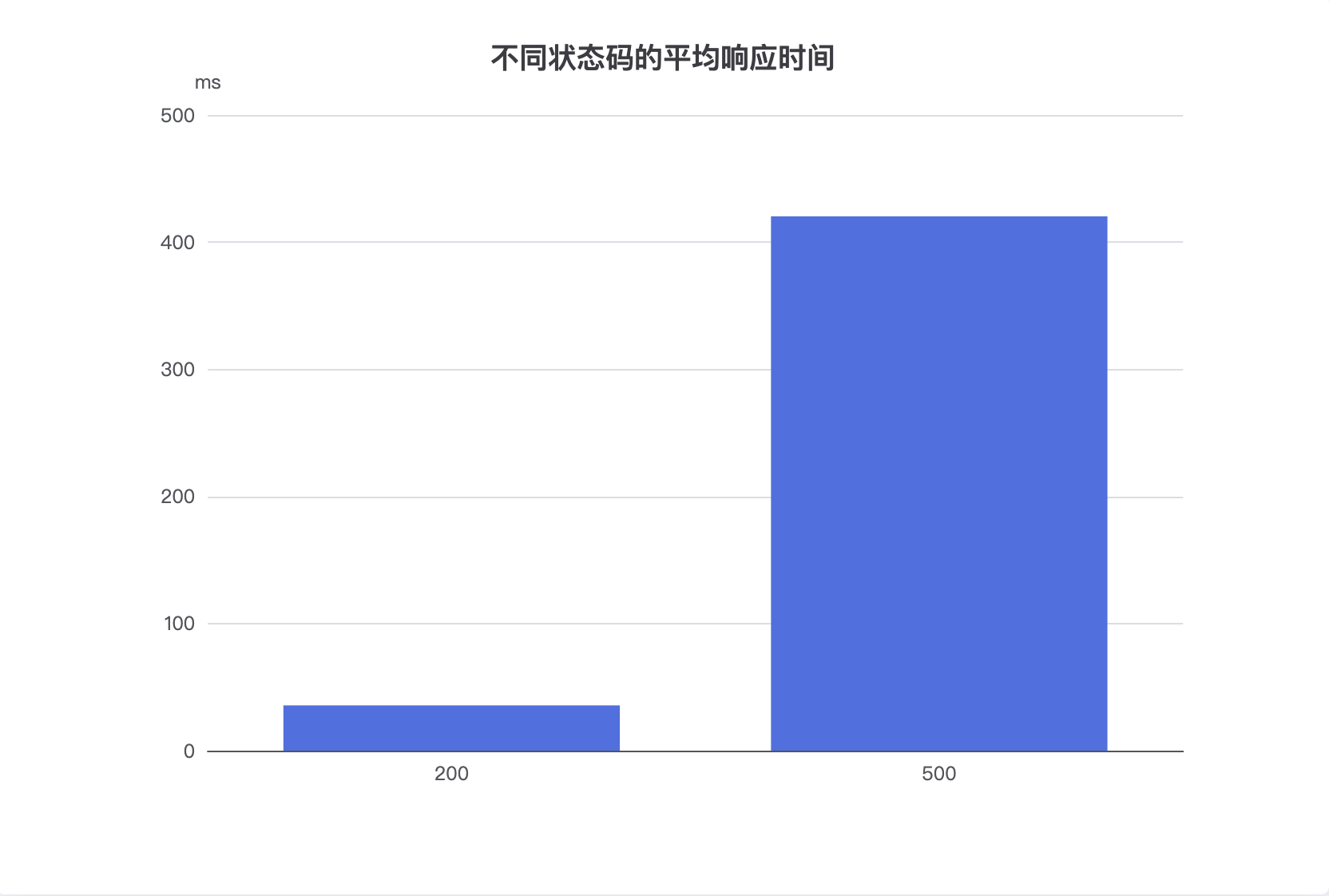
📌 实践价值
- 可以快速发现 异常状态码
- 是 性能监控 / SLA 分析 的基础方式
6.3 date_histogram 聚合 + 折线图:趋势分析
#
场景说明 #
按 天 统计访问量变化趋势,用于流量监控。
① Easysearch 聚合查询 #
GET logs/_search
{
"size": 0,
"aggs": {
"visits_over_time": {
"date_histogram": {
"field": "@timestamp",
"calendar_interval": "day"
}
}
}
}
② 返回结果(简化) #
{
"aggregations": {
"visits_over_time": {
"buckets": [
{
"key_as_string": "2025-01-01",
"doc_count": 1200
},
{
"key_as_string": "2025-01-02",
"doc_count": 1780
},
{
"key_as_string": "2025-01-03",
"doc_count": 2156
},
{
"key_as_string": "2025-01-04",
"doc_count": 2067
},
{
"key_as_string": "2025-01-05",
"doc_count": 2654
}
]
}
}
}
③ 前端数据处理 #
const buckets = response.aggregations.visits_over_time.buckets;
const xAxisData = buckets.map((b) => b.key_as_string);
const seriesData = buckets.map((b) => b.doc_count);
④ 使用 ECharts 渲染折线图 #
const option = {
title: {
text: "每日访问量趋势",
},
xAxis: {
type: "category",
data: xAxisData,
},
yAxis: {
type: "value",
},
series: [
{
type: "line",
data: seriesData,
smooth: true,
},
],
};
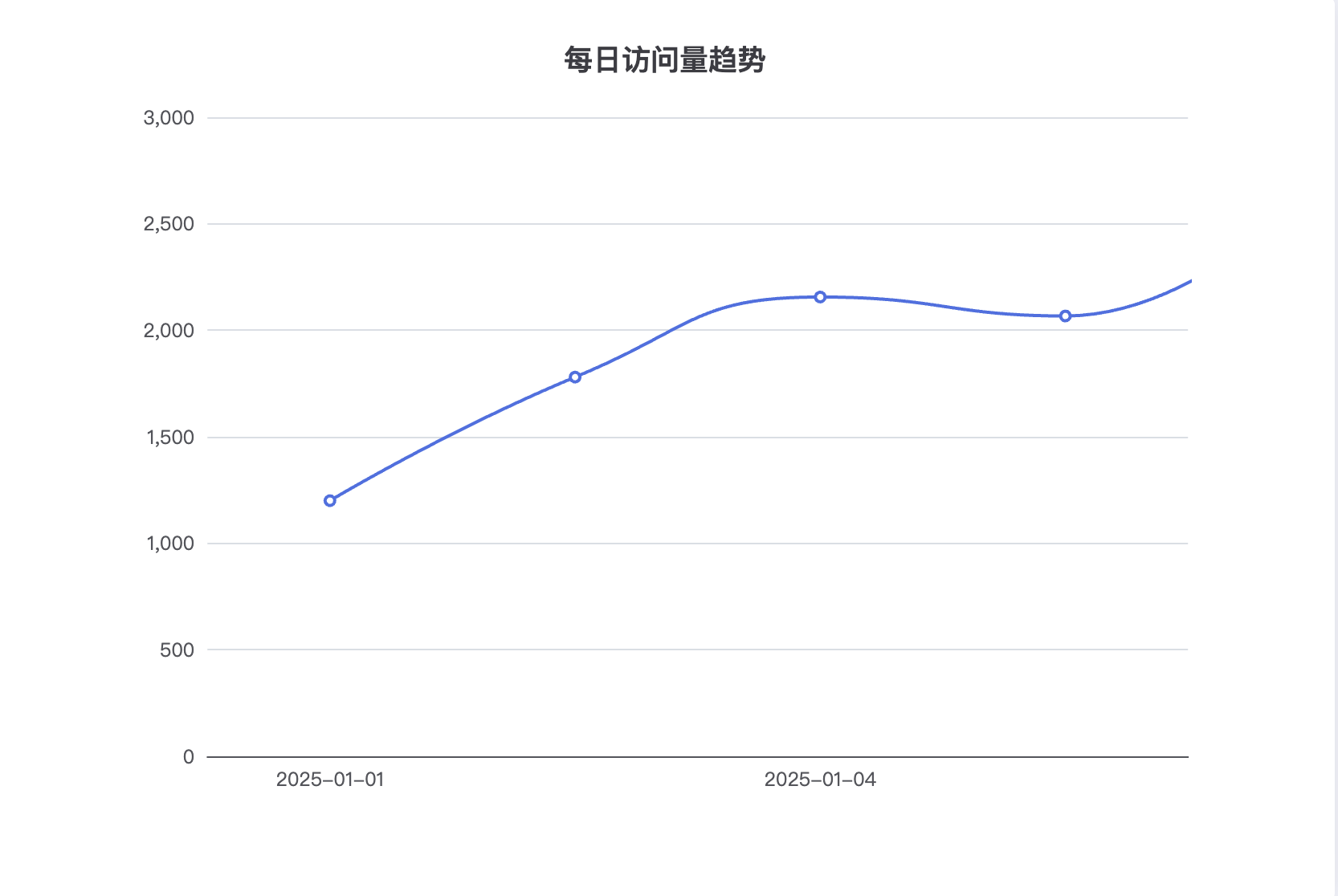
📈 适用场景
- 访问量趋势分析
- 业务增长监控
- 异常流量识别
6.4 可视化实践总结 #
| 聚合类型 | 常见图表 | 典型用途 |
|---|---|---|
| terms | 柱状图 / 饼图 | 分类统计 |
| terms + avg / sum | 柱状图 | 分类指标分析 |
| date_histogram | 折线图 / 面积图 | 时间趋势分析 |
核心思想只有一句话:Bucket 决定“分组维度”,Metric 决定“统计值”,图表只是结果的呈现方式。
7. 总结 #
| 聚合类型 | 作用 |
|---|---|
| Bucket 聚合 | 对数据分类分组,例如按字段值划分桶 |
| Metric 聚合 | 对数据或分组做统计,例如平均值、总和等 |
聚合的真正价值在于组合使用:先分组,再对每组做统计,这样才能得到对业务有意义的分析结果。
掌握 terms、avg、sum 等聚合类型后,你就可以用 Easysearch 构建灵活的数据统计分析与可视化功能,为业务洞察与数据驱动决策提供坚实基础。

