
















在之前的文章中,我们已经见识了 Easysearch 在开发和运维上的便捷。但当数据量从 GB 增长到 TB 甚至 PB 级别时,一个根本性的问题摆在了我们面前:单台服务器的物理极限,如何被打破?
这正是“分布式”大显身手的舞台。Easysearch 天生就是一个分布式系统,它的强大并非源于单个节点的“蛮力”,而是其背后一套优雅、高效的集群协作机制。
今天,让我们用一个“创业公司”的比喻,来为你图解 Easysearch 集群是如何通过精妙的组织架构,从容应对海量数据挑战的。
1. 痛点:当一个办公室再也装不下所有档案 #
想象一下,我们的应用是一家创业公司,数据就是客户档案,而服务器就是一个办公室。
当公司规模很小时,一个办公室足以应对所有业务。但随着客户档案(数据)越来越多,三个致命的问题出现了:
- 柜子不够用 (存储瓶颈):办公室的物理空间有限,磁盘总有被塞满的一天。
- 前台忙不过来 (性能瓶颈):一个前台(CPU/内存)要同时应付成百上千的查询和录入请求,最终不堪重负。
- 失火风险 (单点故障):万一这个办公室遭遇断电、火灾等意外,所有客户档案将毁于一旦,公司直接倒闭。
为了解决这些问题,公司决定开设分部,建立一套分布式协作系统。这,就是 Easysearch 集群的由来。
2. 核心战略一:分而治之 (Sharding) #
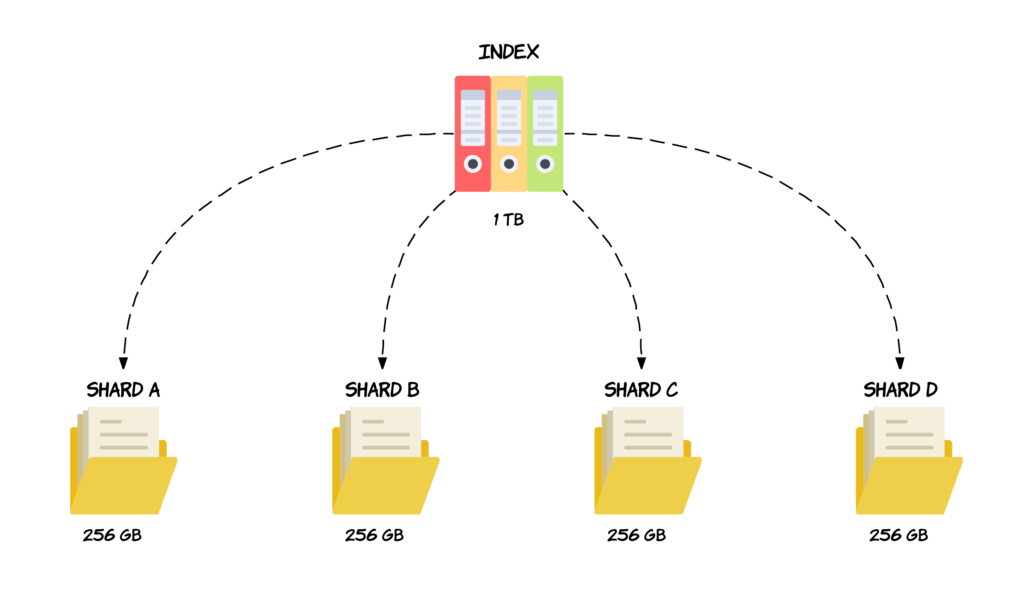
面对堆积如山的客户档案(一个巨大的索引),CEO 的第一个决策是:不能把所有档案都放在一个柜子里,必须分卷存放!
这就是分片 (Sharding) 机制。Easysearch 会自动将一个索引(Index)切分成多个独立的主分片 (Primary Shard)。
- 比喻:一套名为“全国客户”的档案柜,被拆分成了 3 个分卷:
- P0 (主分片0):存放
A-G开头的客户档案。 - P1 (主分片1):存放
H-P开头的客户档案。 - P2 (主分片2):存放
Q-Z开头的客户档案。
- P0 (主分片0):存放
然后,公司将这 3 个分卷,分别交由 3 个不同的分部办公室(节点)来保管。
关键点:
- 路由规则:当一份新档案进来时,Easysearch 会根据档案的 ID(或指定的路由键)通过哈希算法(
hash(doc_id) % 3)精确计算出它应该存放到哪个分卷。 - 不可变更:主分片的数量在创建索引时就必须确定,且之后不能更改。就像档案柜的分卷规则一旦定下,后续要修改会非常麻烦。
通过分片,Easysearch 将存储和计算压力分散到了多个节点,完美解决了“柜子不够用”和“前台忙不过来”的问题。
3. 核心战略二:万无一失 (Replication) #
解决了容量和性能问题后,CEO 开始担心“失火风险”。如果上海分部(Node 1)掉线了,那 A-G 的客户档案不就全丢了吗?
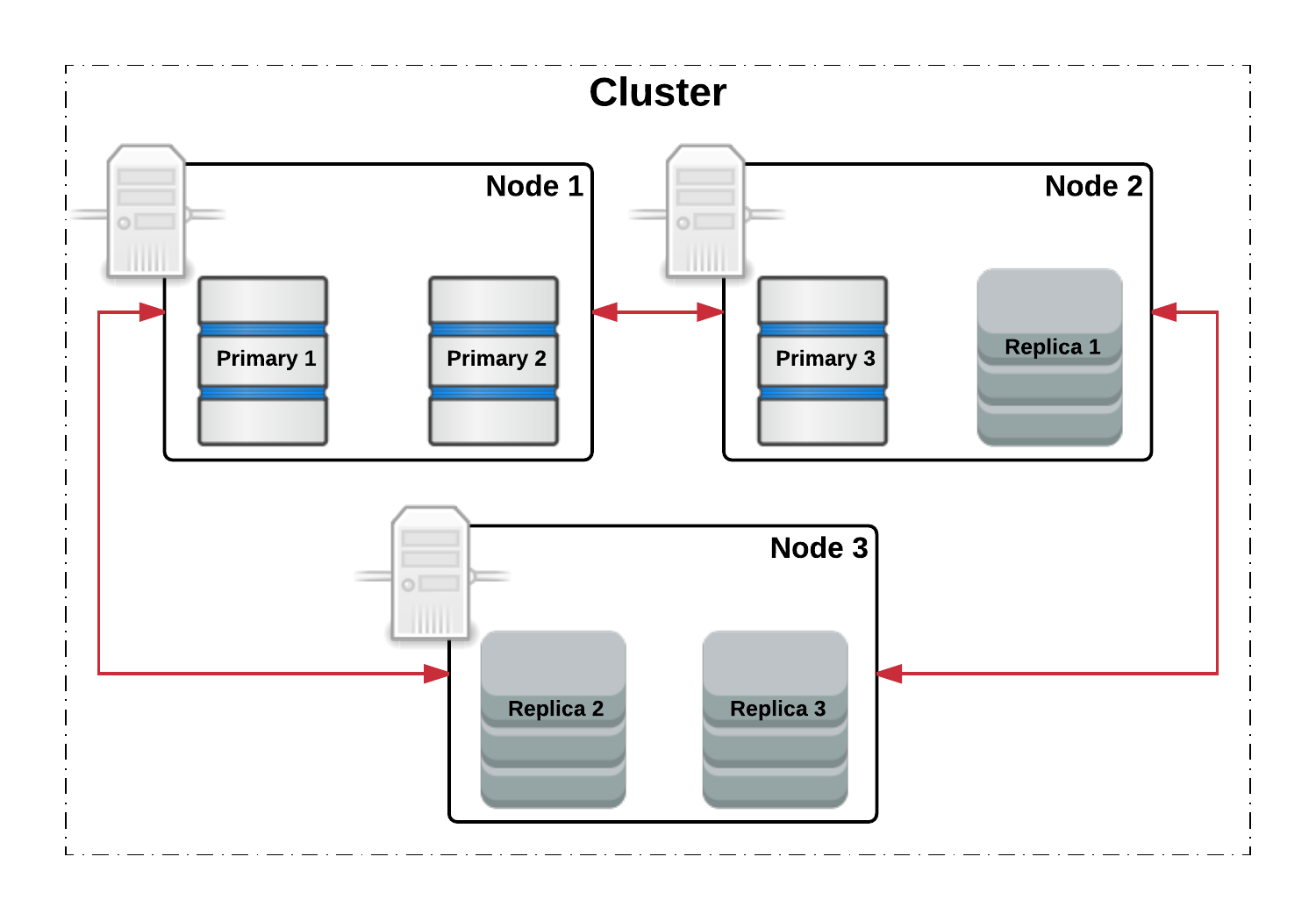
于是,第二个战略出台:所有档案分卷,都必须复印一份,存放到另外一个分部去!
这就是副本 (Replication) 机制。Easysearch 会为每个主分片创建若干个副本分片 (Replica Shard)。
- 比喻:
- P0 的原件在上海,它的复印件 R0 (副本0) 必须放在北京。
- P1 的原件在北京,它的复印件 R1 (副本1) 必须放在深圳。
- P2 的原件在深圳,它的复印件 R2 (副本2) 必须放在上海。
关键点:
- 高可用性:当持有主分片 P0 的 Node 1 宕机时,集群会自动将 R0 提升 (Promote) 为新的主分片。整个过程对用户是透明的,服务不会中断。
- 写入流程:新的档案总是先送到“原件”所在的办公室(Primary Shard),该办公室负责处理,并自动将变更同步给所有“复印件”办公室(Replica Shards)。
- 提升读性能:查询请求可以发送到任何一个持有档案的办公室,无论是原件还是复印件都可以处理。这使得副本分片也能分担读请求的压力。
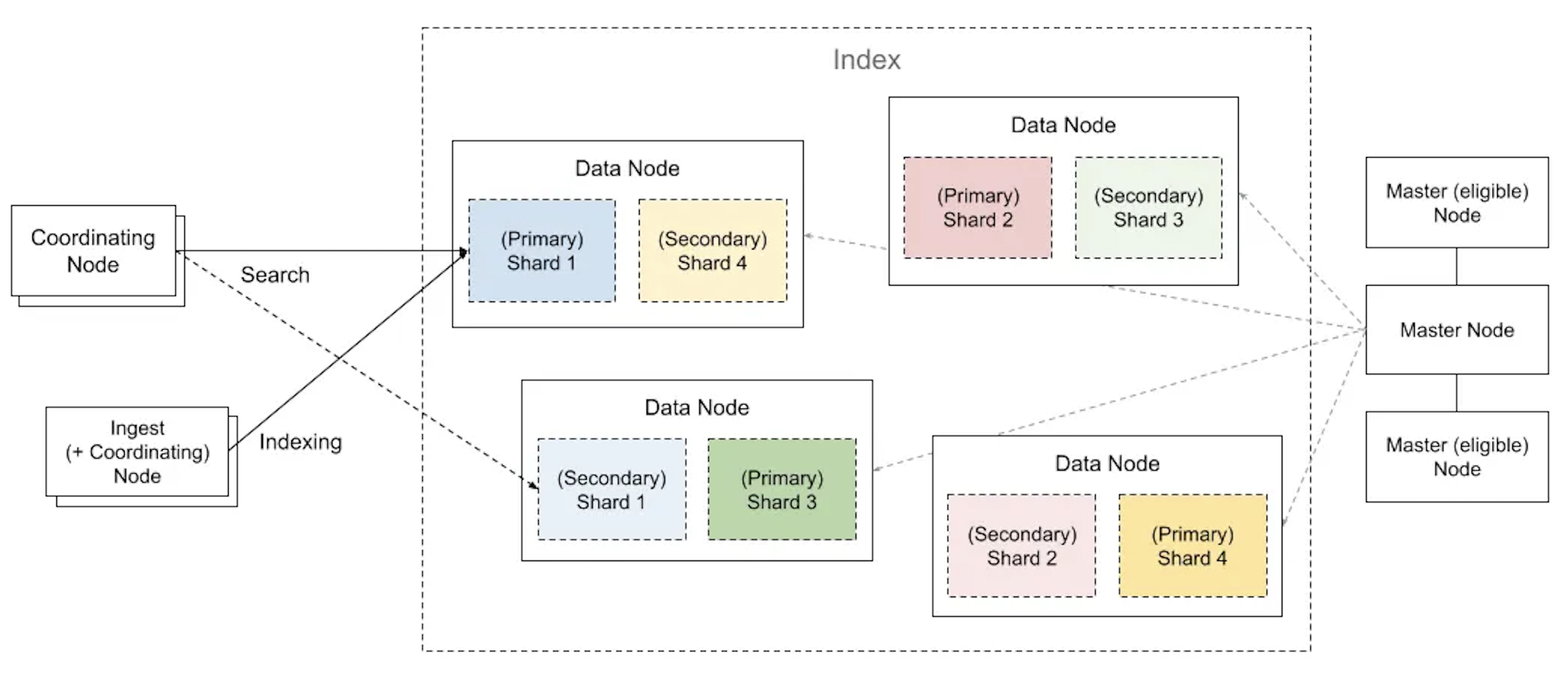
4. 公司的组织架构:节点角色 (Node Roles) #
随着分部越来越多,公司需要一个清晰的组织架构来确保高效运作。在 Easysearch 集群中,每个节点(办公室)可以扮演不同的角色。
- 总指挥 (Master Node):
- 职责:集群的 CEO,有且仅有一位。它不负责存储数据,只负责管理集群的“元信息”,如:批准创建/删除索引、决定分片如何分配、监控所有节点的状态。
- 重要性:Master 节点非常关键,但它的工作负载通常很轻。
- 业务骨干 (Data Node):
- 职责:公司的核心业务部门。它们负责存储数据(持有分片)、处理数据的增删改查和聚合分析。
- 特性:Data 节点是资源消耗大户,需要大量的 CPU、内存和磁盘。
- 前台总机 (Coordinating Node):
- 职责:这并非一个特定的角色,而是所有节点都具备的能力。当一个节点收到外部请求时,它就扮演了“协调节点”的角色。它负责解析请求、将请求转发给正确的 Data 节点、汇总结果,最后返回给客户端。
5. 健康晴雨表:Green, Yellow, Red #
为了实时了解公司的运营状况,Easysearch 提供了一个非常直观的健康状态指示灯。
- 绿色 (Green):万事大吉,高枕无忧。
- 状态:所有主分片和副本分片都正常分配,各就各位。公司处于最健康、最安全的状态。
- 黄色 (Yellow):紧急预警,存在风险!
- 状态:所有主分片都正常(意味着数据没有丢失,服务完全可用),但至少有一个副本分片未能成功分配(比如某个节点临时掉线了)。
- 解读:公司虽然能正常运营,但已经失去了“备份”,处于“单点故障”的风险中!需要运维人员立刻介入排查。
- 红色 (Red):灾难,部分业务瘫痪!
- 状态:至少有一个主分片未能成功分配(例如,持有 P0 的节点和持有 R0 的节点同时宕机)。
- 解读:这意味着一部分数据(例如
A-G的客户档案)彻底无法访问。虽然其他分片的数据可能仍然可用,但集群已经处于不完整状态。
总结:一个高效协作、自我修复的团队 #
现在,让我们把所有环节串联起来:
Easysearch 集群就像一个高度协同的团队。通过分片 (Sharding),它将不可能完成的任务分解;通过副本 (Replication),它为每一次任务提供了容灾备份;通过明确的节点角色 (Node Roles),它确保了权责分明、高效协作。
它的强大,不在于单个节点有多么强悍,而在于它建立了一套自我管理、自我修复的分布式协作机制。正是这套机制,让它能够将成千上万台普通的服务器,组织成一个能够支撑海量数据的强大搜索引擎。

